Or try one of the following: 詹姆斯.com, adult swim, Afterdawn, Ajaxian, Andy Budd, Ask a Ninja, AtomEnabled.org, BBC News, BBC Arabic, BBC China, BBC Russia, Brent Simmons, Channel Frederator, CNN, Digg, Diggnation, Flickr, Google News, Google Video, Harvard Law, Hebrew Language, InfoWorld, iTunes, Japanese Language, Korean Language, mir.aculo.us, Movie Trailers, Newspond, Nick Bradbury, OK/Cancel, OS News, Phil Ringnalda, Photoshop Videocast, reddit, Romanian Language, Russian Language, Ryan Parman, Traditional Chinese Language, Technorati, Tim Bray, TUAW, TVgasm, UNEASYsilence, Web 2.0 Show, Windows Vista Blog, XKCD, Yahoo! News, You Tube, Zeldman
Perplexity launches Sonar API, enabling enterprise AI search integration | InfoWorld
Technology insight for the enterprisePerplexity launches Sonar API, enabling enterprise AI search integration 22 Jan 2025, 10:42 am
Perplexity has introduced an API service named Sonar that would allow developers and enterprises to embed the company’s generative AI search technology into their applications.
The company has rolled out two initial tiers – a more affordable and faster option called Sonar, and a higher-priced tier, Sonar Pro, tailored for handling more complex queries.
{kind=link}
How to deal with a Big Pile of Mud 22 Jan 2025, 10:00 am
Last week I talked about where those big, unwieldy code bases come from. They don’t appear out of nowhere, and no one ever plans to create one. Defining a problem is great, but what is one to do? How will you deal with the Big Pile of Mud that you inherited?
It’s tempting — and I see this temptation indulged all the time — to stamp your feet and bitch and moan about the big mess you have. I am sorry to say that I’ve been a staunch complainer in these situations in the past. How could anyone have been so foolish? No developer could actually be this bad, right? What were they thinking?
Go ahead and indulge. Feel all the feels. But keep it to yourself, get it all out, and get over it. Because the first step to addressing the problem is to accept that you have the Big Pile of Mud.
Step 1. Embrace the mud
Instead of giving in to the anger and blame, it’s important to realize that this Big Pile of Mud works and puts food on the table for you and everyone in your company. Sure, it’s a mess, but it pays the bills. You might hate it. It might make you frustrated and angry. But you need to just swallow all of that and move on with the job of fixing the pile and making the mud do new things.
Once you are past all that, the next thing is to remember that the best thing to do when you are in a hole is stop digging. Job one is not to make things any worse than they already are. Don’t add another layer of depth to that huge, nested if statement. Don’t add 120 more lines of code to that God class. Don’t follow those old patterns of coupling things together and making one thing do fourteen things and mashing concerns together. In other words, don’t make any more mud.
Step 2. Apply the Boy Scout rule
The first standard you should set is to always apply the Boy Scout Rule to your code. That is, always leave it a little better and a little neater than you found it. For instance, if you find code that isn’t formatted to the company’s formatting standards, format it properly. If you find code that has crappy variable names, change them to be more descriptive. If you find code that has lines of code that do seven things, refactor out to explaining variables. Set a policy that the time spent improving code as you run across it, even in little ways, is well worth it.
Also as a rule, always delete commented-out code and other dead code. For reasons I have never quite understood, many developers like to comment out code instead of deleting it. I guess they think they’ll need it later? I don’t know. In any event, if you run across commented-out code, just delete it. If you do end up needing it, it’s safely there in your source control repository. Can you tell this is kind of a pet peeve of mine?
Step 3. Refactor high and low
Next up — refactor judiciously. The first refactoring you should do is to pull out code that is inside if statements and organize it into separate procedures. Almost every huge routine I’ve ever seen is made up of a large number of nested if statements. You can get an easy win by highlighting all that code inside each branch of each if statement and creating a separate procedure for it. This alone will start simplifying your code base. By the same token, never write more than a few lines of code inside an if branch in any new code you write.
And for all new code that you write, commit to putting all new logic into separate classes, and call the methods of those classes instead of just piling code into ever larger methods. Apply the single-responsibility principle as best you can, and try to keep each thing that needs doing separate and uncoupled. This is probably the most important “stop digging” action you can take. Just refuse to pile up those methods that have more and more nested code.
Step 4. Break up dependencies
Finally, after applying these basic, relatively safe refactorings, endeavor to be a bit braver and start refactoring more deeply. Continue to break down functionality into classes, and write unit and integration tests for these new classes. You should make sure that all new code you write is testable. Start breaking dependencies by using dependency injection. This too is critical to stopping the digging because its use will stop dependency coupling in its tracks. Certainly apply the principle to all of your new code, and slowly start refactoring your existing work.
Ultimately, dealing with a Big Pile of Mud involves a commitment to breaking old, bad habits and implementing new, good habits. You won’t always be able to fix a bug in the best possible way, and large compromises may sometimes be necessary when adding new features. But if you keep your head up and your eyes open, that messy, embarrassing code base can both improve and continue to pay your salary.
{kind=link}
State of JavaScript: Highlights of the JavaScript developer survey 22 Jan 2025, 10:00 am
Getting a complete picture of the multi-headed beast that is the JavaScript ecosystem isn’t easy, but the annual State of JavaScript survey is a good place to start. What makes this survey stand out is that it attracts the input of thousands of working developers and other JavaScript enthusiasts. Reading it gives you a real sense of the movements that are defining the language and its ecosystem.
Here I’ve collected my key takeaways from the recently released 2024 State of JavaScript survey, starting with a look at one of the most important trends currently rocking the world of software development. We’ll also look at ongoing pain points, popular new language features, and a plethora of tools and frameworks ranked by popularity and use.
AI code generators
Despite all indications that AI is eating programming, 14% of developers responding to the 2024 State of JavaScript survey said they did not use any AI code generator at all. For developers who were leaning on AI copilots, ChatGPT was #1 (67%), followed by GitHub Copilot (48%), Claude (23%), and Gemini (14%).
JavaScript pain points
It turns out some JavaScript developers still want static types, with 32% of respondents identifying the lack of types as painful. One of the proposals making the rounds is Type annotations, which would allow coders to opt-in to static types directly in JavaScript.
A question that arises is what would happen to TypeScript if JavaScript were to gain static types. However, it seems that adding this feature is a slow process, in part because many developers are content with TypeScript. The advantage of adding types to the JavaScript spec would be eliminating the compilation step that TypeScript requires. With close to a third of developers still interested, it seems only a matter of time before static types are accessible directly in JavaScript.
Pain points in features and usage
At a higher level, developers noted they are missing features found in other languages, including a standard library (43%), Signals (39%), and a pipe operator (23%). Another category of pain point is usage, where developers noted deficiencies in architecture (35%) and state management (31%), followed by dependency management (29%), build tools (28%), and performance (24%).
Newer JavaScript language features
JavaScript and its feature set are always evolving. This year’s survey asked developers which of several newer syntax features they were using. Three rose to the top.
Nullish coalescing
You are surely still programming in 2023 if you haven’t at least experimented with the concise beauty of the nullish coalescing operator, introduced in ECMAScript 11. But that’s okay: it only takes about five minutes to get the gist of the ?? syntax. Here’s an example of how to use it to replace explicit null checks on an object chain:
let machineStatus = report?.machine?.status ?? "No thinking machines!";
If report or machine are null, the expression will short-circuit and machineStatus will default to “No thinking machines!”
According to the survey, a full 85% of respondents have adopted this operator in their code.
Promise.allSettled() and Promise.any()
A Promise is a handy way to deal with asynchronous operations and the allSettled() and any() methods give you a simple way to say: wait for all or any of the operations to complete. These are two very common needs in async, and developers are taking to the new syntax, with 47% of respondents saying they use allSettled() and 43% any().
Array.toSorted()
Forty percent of respondents have started using Array.toSorted, and it’s easy to see why. It takes a common need—sorting an array of values—and makes it simple. It uses natural order (like alphanumeric for strings) by default, but you can also provide a sort function:
const spiceInventory = [
{ spice: 'Melange', quantity: 500 },
{ spice: 'Sapho', quantity: 100 },
{ spice: 'Rakis', quantity: 200 }
];
// Sort by quantity in descending order
const sortedInventory = spiceInventory.toSorted((a, b) => b.quantity - a.quantity);
Set methods: union, intersection, difference
A Set is a collection with no duplicates, drawn from set theory. Sets will always be somewhat narrow in their use; in fact, currently 76% of respondents say they have yet to use the new feature in JavaScript. Nonetheless, Sets are perfect for some scenarios, and some are starting to catch on:
Set.union()—used by 16% of respondents
Merge sets:
const set1 = new Set([1, 2, 3]);
const set2 = new Set([3, 4, 5]);
const unionSet = set1.union(set2); // Result: Set {1, 2, 3, 4, 5}
Set.intersection()—used by 15% of respondents
Find the shared parts:
const set1 = new Set([1, 2, 3]);
const set2 = new Set([3, 4, 5]);
const intersectionSet = set1.intersection(set2); // Result: Set {3}
Set.difference()—used by 15% of respondents
Find the different elements:
const set1 = new Set([1, 2, 3]);
const set2 = new Set([3, 4, 5]);
const differenceSet = set1.difference(set2); // Result: Set {1, 2}
Object.groupBy()
Another new feature, Object.groupBy(), gives you a dead-simple mechanism for organizing objects according to a property. As of the 2024 survey, 33% of respondents indicate they have used it. This is one of those features you’ll likely ignore until you need it—and then you’ll find it’s the perfect solution for your problem:
const books = [
{ title: "The Hitchhiker's Guide to the Galaxy", genre: "Science Fiction" },
{ title: "Pride and Prejudice", genre: "Romance" },
{ title: "The Lord of the Rings", genre: "Fantasy" },
{ title: "1984", genre: "Science Fiction" }
];
const booksByGenre = Object.groupBy(books, (book) => book.genre);
/* Gives you:
{
"Science Fiction": [
{ title: "The Hitchhiker's Guide to the Galaxy", genre: "Science Fiction" },
{ title: "1984", genre: "Science Fiction" }
],
"Romance": [
{ title: "Pride and Prejudice", genre: "Romance" }
],
"Fantasy": [
{ title: "The Lord of the Rings", genre: "Fantasy" }
]
} */
Libraries and frameworks
The State of JavaScript survey captures an enormous amount of data about the tools and frameworks developers are using, including the current general sentiment about each tool and changes in sentiment and usage over time.
This ingenious chart takes a wide view, showing sentiment change over time for build tools, front end, back end, meta-frameworks, and testing tools. We’ll look more closely at a few specific categories.
Front-end frameworks
- Angular is in an interesting moment, as it bounces off a long-term decline in popularity to recover strongly in both “positive opinion” sentiment and usage. As of the 2024 survey, Angular has successfully pulled itself out of the “little used/unliked” quadrant. This framework might be worth a look if you haven’t checked it out in a while.
- Svelte and Vue: These two open-source darlings are neck-and-neck with “would use again” sentiment at an impressive 88% and 87%, respectively.
- React: The flagship reactive framework remains strong, with a “used it and liked it” rating of 43%. This year’s survey allowed for “used it, no sentiment” and React showed 24% there. Not surprisingly, almost no respondents said they had not heard of React.
Build and repository tools
- Vite is the star among build tools in terms of growing usage and developer sentiment. Fifty-one percent of respondents said they have used Vite and have a positive feeling about it. It’s clearly winning developers over with its take on the build-chain experience. It boasts a 98% retention rate—the highest of all the ranked build tools.
- pnpm is touted as a fast drop-in replacement for
npm, which also supports monorepos. It has 93% positive sentiment and ~42% of respondents said they had used and liked it. Fifteen percent of respondents hadn’t yet heard of it. - After Vite, esbuild is considered the most-loved build tool according to the State of JavaScript survey, with 91% user approval. It touts its speed over other tools and built-in support for JavaScript, TypeScript, CSS, and JSX.
- Another interesting build choice you may not have heard about is SWC, a Rust-based build tool that is meant for speed and one-stop compile/bundle builds. The survey indicates it has an 86% positivity rating.
Testing tools
On to the onerous, must-do task of testing. Just kidding, sort of. Fortunately, there are plenty of frameworks to help with testing, and a few stood out.
- Right alongside Vite is its testing framework, Vitetest, with 98% retention among users. A library to check out if you are ever forced to do testing.
- Another contender is Playwright, also very popular with a 94% “would use again” rating from users.
- The aptly named Testing Library shows 91% positive sentiment among users.
Meta-frameworks
The 2024 survey shows a subtle but discernible downturn in user sentiment about meta-frameworks, even while actual usage continues to increase.
- Astro.js is a standout among meta-frameworks. Its usage is growing rapidly, and while its “positive sentiment” shows a slight decline over time, 94% of users said they “would use it again.” The upshot is that Astro.js remains a rising star in its class.
- With a “would use again” rating of 90%, SvelteKit continues to be a popular meta-framework option. In line with the general trend, its sentiment has declined somewhat over the past couple of years.
- The pioneer and still the most popular of the meta-frameworks by far, Next.js is holding steady against last year in usage, while its sentiment has declined sharply to a still-solid 68%.
Other notable libraries
The survey covers quite a few other libraries, as well. Two notables are Lodash, which 43% of respondents reported using regularly, and Three.js, the premier 3D library for JavaScript. It’s worth visiting the Three.js website just to explore demos like this one. Now that’s just neat.
Hosting services
AWS is still the most popular cloud hosting service—but not by much! Here’s a quick rundown of the most popular by survey respondents:
- AWS—44%
- Vercel—40%
- GitHub Pages—38%
- Netlify—38%
- Cloudflare—21%
- Heroku—19%
The story here seems to be that the top four hosting platforms are the kings of JavaScript hosting, with everyone else bringing up the rear.
Conclusion
The JavaScript ecosystem continues to be a festival of evolving tools, frameworks, and features. The most recent State of JavaScript survey gives us an extremely useful way to stay up to date and get a good look at things.
{kind=link}
3 Python web frameworks for beautiful front ends 22 Jan 2025, 10:00 am
Python has long had a presence as a language for server-side frameworks, with support for most every project size or use case. But it’s historically been confined to the back end—there’s no real culture of writing Python for creating front-end, client-side code. At least not yet.
Recently, some projects have tried to transpile Python to JavaScript on the front end, or run Python on the front end via WebAssembly. There’s promise in the idea, but the way it’s currently implemented is clunky and primordial. Maybe there’s a better option out there?
Sure enough, there is. An emerging family of Python web frameworks let you write declarative Python code on the back end that programmatically generates front-end code. You can use Python objects to describe HTML entities and their JavaScript-powered behaviors, then let the framework generate those objects for you when they’re served to the client.
We’ll look at three Python web frameworks that follow this paradigm, allowing you to describe front-end code (HTML, CSS, and JavaScript) using back-end Python code. The front-end objects are represented through the Python object model.
Anvil
Anvil‘s big pitch is “Build web apps with nothing but Python” (emphasis theirs). With Anvil, one writes Python code—or uses Anvil’s drag-and-drop low-code tools—and out comes a full-blown web application with an interactive, JavaScript-powered front end and a Python-powered back end.
Anvil offers two basic approaches. One is the Anvil cloud service, which comes in a range of pricing tiers and offers visual build tools and various hosting options. The other is the open source Anvil runtime, which doesn’t include the visual designer but still lets you build and run Anvil applications with hand-written code.
Anvil applications consist of three components: the UI, which can either be designed with Anvil’s design tools or expressed through hand-written code; the client-side code that’s transpiled from Python to JavaScript; and the server-side Python code. The Anvil cloud editor automatically generates back- and front-end code, in much the same manner as tools like Qt Design Studio.
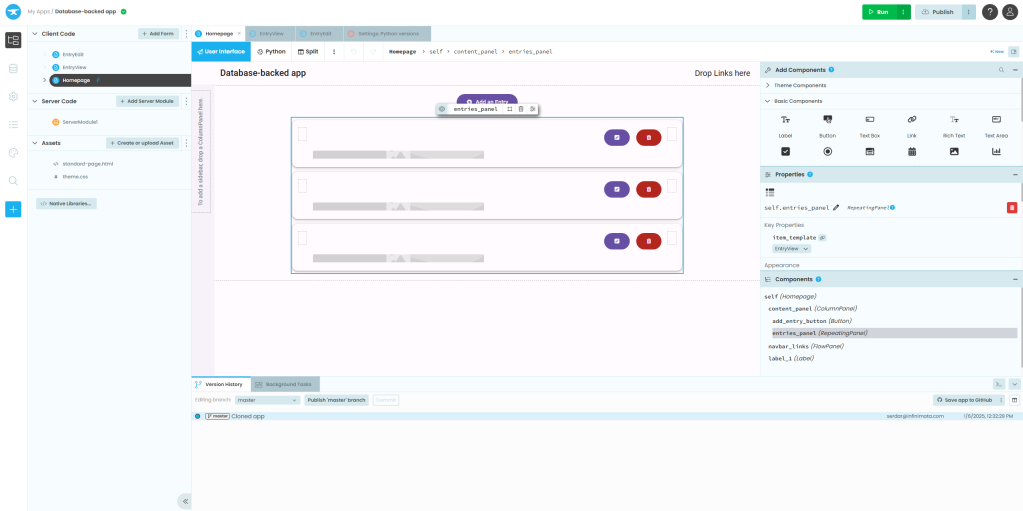
Anvil’s cloud incarnation provides a powerful visual design tool for your UIs. Once it’s generated, you can re-use the code without the designer.
IDG
The Anvil cloud editor comes with a few included examples, such as a basic static application with no back-end code, a simple ticketing system, or a full-blown online store. Each can be used as a template for your own project. You also get a useful selection of prebuilt UI components to wire into web pages. One handy component is a timer for executing code at intervals—e.g., for polling a data source for updates. You can also hand-roll your own HTML and custom components. Data sources can also be added in the cloud and wired to components, so you can put together common CRUD apps very quickly.
If you elect to use the Anvil runtime, you can write applications by hand and use one of a few prebuilt templates as a starting point. Changes to the code are reflected immediately on the application server, making for a fast development cycle. User interface elements are essentially Python class instances, with event handlers added via class methods. It’s also easy to programmatically add behaviors by way of well-thought-out general methods. For instance, if you want to raise an event with an object’s children, you don’t need to loop through the children to do it; you can simply use a raise_event_on_children method on the container object.
By default, all the JavaScript for an Anvil site is generated automatically, but you can write your own JavaScript as needed. Note, though, that Anvil loads some JavaScript of its own that might conflict with the code you write. What’s more, some of Anvil’s own dependencies are somewhat dated—Bootstrap 3, for instance. You can work around it by creating a custom theme, which is not a trivial amount of work.
Reflex
Reflex (formerly Pynecone) doesn’t include the design tooling found in Anvil, but it has the same underlying idea: You use Python code both to write the back end of your web stack and to programmatically generate the front end without needing to write JavaScript.
Reflex’s earlier incarnation used both Python and the long-term support version of the Node.js runtime. Reflex needs nothing more than Python 3.8 or better, and works on Linux and Windows, although Windows users are advised to use WSL for the best performance. Once you get things set up, you can use the provided reflex command to set up a new Reflex project and get it running.
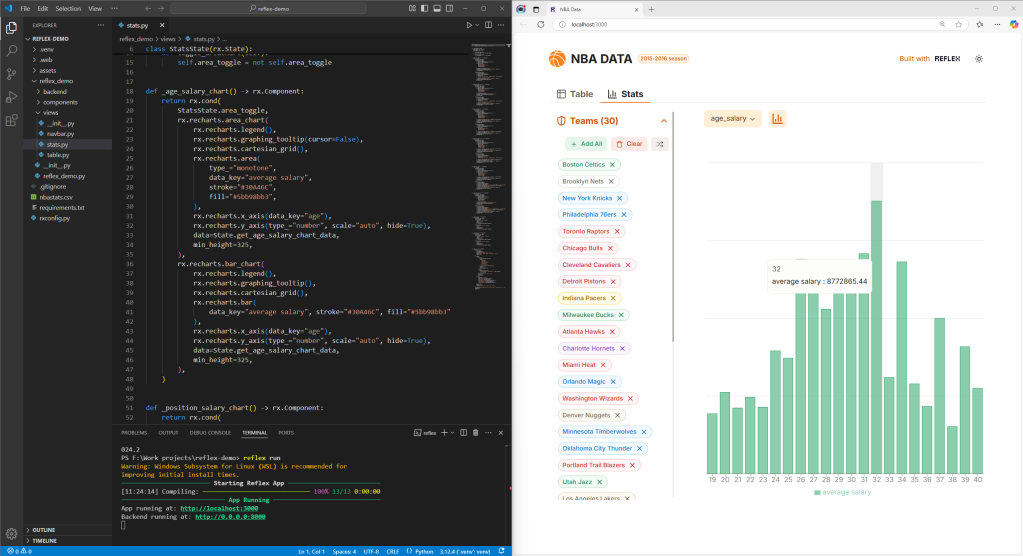
A sample Reflex web app created in pure Python. The interactive chart is one example of many such widgets bundled with Reflex.
IDG
The front end of a Reflex app compiles to a React application, with FastAPI to serve the Python back end. Many common components come built-in—not just things like text layouts or form handling, but data display objects like plots or charts, feedback controls like alerts and progress bars, and overlay objects like modals and tooltips. You can also wrap custom-built React components. For connecting to data sources, React includes a data layer that wraps the well-known SQLAlchemy ORM.
If you want to customize a UI component, most common customizations, like CSS styling, can be passed as arguments to the object constructor, rather than subclassing a component and modifying it that way. For everything else, there’s custom HTML, but some combination of the built-ins and their options should suffice for the vast majority of common projects.
Finally, if you build chiefly static sites, Reflex has the handy ability to export an entire site’s front end to a static build. This makes Reflex useful as a programmatic site generator tool, as well.
NiceGUI
Picture this: You’ve got an existing Python app that runs as a command-line application or web service, but you want to add a web-based UI to it—and fast. You could try cobbling together a front end on your own, but why reinvent that wheel when NiceGUI has already done it for you?
NiceGUI uses a declarative syntax to describe what your UI components look like and how they behave. The gallery of prebuilt UI components includes many common widgets—buttons, sliders, text labels, input boxes, file uploaders, and so on. But they also include components for more sophisticated applications, like audio or video, interactive data presentations (charts, tables, Matplotlib figure rendering), 3D visualizations using three.js, CodeMirror editors, and much more. None of these components require you to write any in-browser code at all; NiceGUI handles all of that.
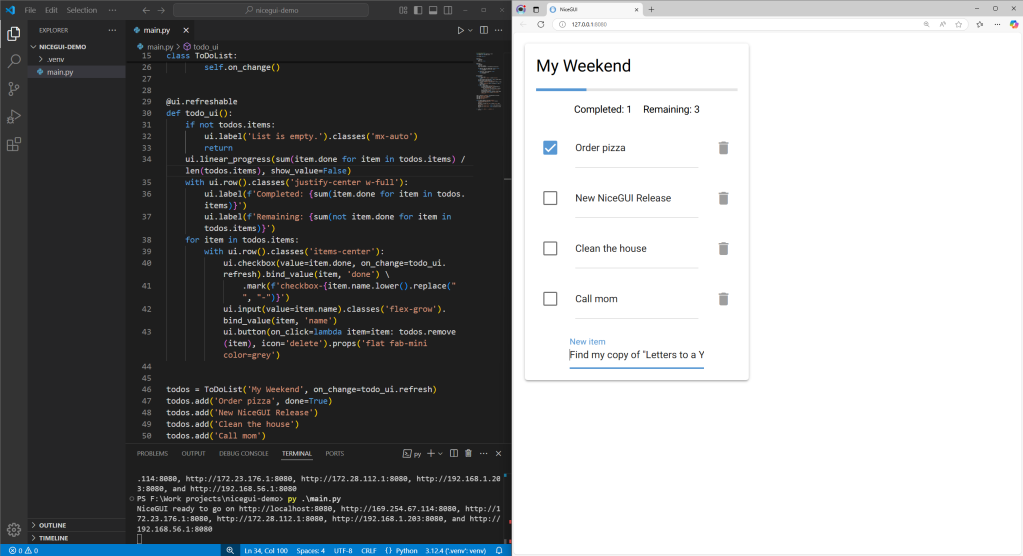
A simple NiceGUI app, with web widgets created programmatically. The resulting app can be deployed on a server or as a standalone program.
IDG
Wrapping existing code with NiceGUI requires learning a little about how NiceGUI handles things like event loops and application state. The good news is all of those things are done by way of high-level constructs in NiceGUI itself. For instance, the ui.timer object lets you quickly define some code to run on a regular interval, or to call once. ui.clipboard and app.storage deal with the browser’s clipboard and local storage mechanisms. And long-running tasks can be easily delegated to a subprocess with run.cpu_bound or to a thread with run.io_bound.
NiceGUI uses FastAPI as its internal web framework, so hosting NiceGUI apps follows many of the same patterns as setting up a FastAPI app. You can also use a prebuilt Docker image as the basis for creating a Dockerized version of a NiceGUI app, or bundle your app as a standalone executable for easy redistribution.
Conclusion
Anvil’s big draw is its low- and no-code interactive UI creation tools. Reflex is convenient if you want to work with a React front end and render generated sites to static HTML. And NiceGUI offers many high-level, declarative abstractions for quickly creating apps, including event handling. All three are solid frameworks that let you write Python code to describe HTML entities and their JavaScript-enabled behaviors.
{kind=link}
Software bill-of-materials docs eyed for Python packages 22 Jan 2025, 4:06 am
Software bill-of-materials (SBOM) documents would be used in Python packages as a means to improve their “measurability” and to address the problem of “phantom dependencies” in Python packages, under a Python Enhancement Proposal (PEP) now being floated at python.org.
In explaining the motivation behind the proposal, created January 2, the authors state that Python packages are particularly affected by a phantom dependency problem, meaning they often include software components not written in Python for reasons such as compatibility with standards, ease of installation, or use cases such as machine learning that use compiled libraries from C, C++, Rust, Fortran, and other languages. The proposal notes that the Python wheel format is preferred by users due to its ease of installation, but this format requires bundling shared compiled libraries without a method to encode metadata about them. Additionally, packages related to Python packaging sometimes need to solve the bootstrapping problem, so include pure Python projects inside source code, but these software components also cannot be described using Python package metadata and thus are likely to be missed by SCA tools, which can mean vulnerable software components are not reported accurately. Inclusion of an SBOM document annotating all included libraries would enable SCA tools to reliably identify the included software.
Because SBOM is a technology-and-ecosystem-agnostic method for describing software composition, provenance, heritage, and more, and because SBOMs are used as inputs for software composition analysis (SCA) tools, such as scanners for vulnerabilities and licenses, SBOMs could be used to improve the measurability of Python packages, the proposal states. Further, SBOMs are required by recent security regulations, such as the Secure Software Development Framework (SSDF). Due to these regulations, demand for SBOM documents of open source projects is expected to remain high, the proposal states. Thus the PEP proposes using SBOM documents in Python packages. The proposal delegates SBOM-specific metadata to SBOM documents included in Python packages and adds a core metadata field for discoverability of included SBOM documents.
{kind=link}
The AI security tsunami 21 Jan 2025, 10:00 am
AI isn‘t just changing cloud computing, it’s completely reshaping how we think about security in the cloud—on both sides. Attackers use AI to cause breaches, and enterprises use AI to defend against such attacks. Let me break this down into what‘s happening and what enterprises need to do about it.
First, let’s face the facts: Over 90% of IT leaders are currently rewriting their cloud strategies as AI and hybrid cloud take center stage. This isn’t just a trend; it’s a fundamental shift in how enterprises think about and implement security measures.
The good, the bad, and AI
Here’s what’s interesting: AI plays both offense and defense in cloud security. On the defensive side, AI is helping bolster defenses, identify threats, and accelerate response times. However, this creates an “arms race” between defenders and attackers, as bad actors use AI for increasingly sophisticated attacks.
What’s keeping security leaders up at night? Data security and compliance remain top priorities, with 96% of organizations establishing enhanced security protocols. This isn’t surprising, given the dual-edged nature of AI in security.
Many are prioritizing hybrid cloud and multicloud deployments to better manage security risks and maintain greater control over sensitive data. Organizations actively integrate AI with their cloud strategies, mainly focusing on advanced security and threat detection. This integration primarily aims to enhance operational efficiency and improve data analytics capabilities in security operations.
Organizations have established procedures and policies for data privacy and compliance in cloud environments. Many consider repatriating workloads from public to private clouds, citing security and compliance requirements as a primary driver. This is leading to more repatriation for enterprises, and it is second only to cloud cost as the reason applications and data are being moved back to enterprise data centers.
Organizations are addressing the skills gap by actively hiring new staff skilled in artificial intelligence and machine learning and retraining existing staff. It’s almost impossible to hire from the outside, given the available AI and security skills. Many organizations cite a lack of skilled cloud security professionals as a significant constraint. When I do a post-breach audit, this is mentioned by far as the primary reason a breach occurred in the first place. Again, it’s people, not technology, that are the determining factor.
Rather than simply updating existing systems, organizations are designing entirely new cloud strategies to meet new security requirements. This includes implementing advanced workload-by-workload analysis to determine optimal hosting environments and security measures. Companies are moving away from “one-size-fits-all” solutions toward more flexible and resilient approaches that can adapt to emerging threats. This includes maintaining the ability to transfer workloads seamlessly between different cloud environments.
Getting ahead of the AI security curve
Now that we have covered what companies are doing, what should they do? I have a three-pronged set of recommendations that I give these days.
Embrace AI-powered security automation. The days of manual security monitoring are numbered, meaning you should stop doing it—today. By 2025, AI will be crucial in reducing manual workload in cloud security, particularly in areas like risk attribution and identifying priority issues. This isn’t optional anymore, it’s survival.
Evolve your zero-trust strategy. With the increasing volatility in the geopolitical landscape and the intensity of the AI race, insider threats are becoming a more significant risk. Organizations need to expand their zero-trust strategies beyond traditional boundaries.
Focus on data protection. New security standards are emerging to protect advanced AI models’ weights, ensure secure storage, and prevent unauthorized access. This is critical for protecting AI model data and needs to be part of your security strategy.
A weapon for defense and offense
The intersection of AI and cloud security represents one of the most significant technological shifts in enterprise computing, one that is often misunderstood. Enterprises are embracing AI-powered tools for defense while simultaneously preparing for AI-enhanced threats. This dual nature of AI in security means enterprises must balance innovation with risk management.
Looking ahead through 2025 and 2026, we’ll likely witness unprecedented cyber warfare that will make the 24-hour news channels. AI systems will battle each other; defensive AI systems protecting cloud infrastructure against increasingly sophisticated AI-powered attacks. This will create a new paradigm in security where the speed and complexity of attacks and defenses will far exceed human response capability. So, this is not about hiring better security tech to do the battle; this is about automating the defenses and hiring people who know how to do that. Good luck to all.
{kind=link}
The bitter lesson for generative AI adoption 21 Jan 2025, 10:00 am
The rapid development and improvement in generative AI technology pose a challenge for training and fine-tuning as a sustainable path for adoption. If organizations constantly need to fine-tune new models for specific tasks, they might be in a costly cycle of catching up with new technology. In contrast, prompt engineering and retrieval-augmented generation (RAG) focus on improving the retrieval and integration of information, a process that can continuously benefit from advances in generative technology. This is a more sustainable short-term adoption strategy.
[ This article is an excerpt from Generative Artificial Intelligence Revealed, by Rich Heimann and Clayton Pummill. Download your free ebook copy at the book’s website. ]
In a popular blog post titled “The Bitter Lesson,” Richard Sutton argues that general methods leveraging computation outperform specialized methods in AI research, fundamentally due to the decreasing computation cost over time.
This argument purges research in favor of Moore’s Law and effectively asks the next generation of researchers to do less. However, we believe there is a “bitter lesson” style analysis for generative AI adoption. Specifically, we prefer retrieval-augmented generation and prompt engineering to training and fine-tuning language models—at least as an initial adoption strategy.
The trouble with training and tuning
A bitter lesson would suggest that relying on training or fine-tuning is less efficient and riskier than waiting for newer, perhaps more robust models. Fine-tuning demands substantial resources. Each new domain or significant shift in data distribution may require retraining or updating the model. This process is expensive and doesn’t necessarily generalize across different tasks or datasets without further fine-tuning, making it inefficient when new models or technologies emerge. RAG and prompt engineering allow organizations to adopt generative technology without training anything in the technology stack, which will accelerate adoption, lower costs, and help ease lock-in.
New models will likely incorporate higher-quality training data, better generalization capabilities, and more advanced features such as infinite context windows that reduce the need for fine-tuning. Consequently, software engineers should write abstractions on top of existing models, which can be done much faster and cheaper than training and fine-tuning language models. These abstractions can migrate to newer models, whereas training and tuning cannot. Investing in RAG and prompt engineering allows organizations to be flexible and to adopt technology without the continuous need for retraining, thus aligning with the bitter lesson principle emphasizing the importance of computation and general methods, such as retrieval mechanisms, over specialized solutions.
The rapid pace of innovation and the proliferation of new models have raised concerns about technology lock-in. Lock-in occurs when businesses become overly reliant on a specific model with bespoke scaffolding that limits their ability to adapt to innovations. Upon its release, GPT-4 was the same cost as GPT-3 despite being a superior model with much higher performance. Since the GPT-4 release in March 2023, OpenAI prices have fallen another six times for input data and four times for output data with GPT-4o, released May 13, 2024. Of course, an analysis of this sort assumes that generation is sold at cost or a fixed profit, which is probably not true, and significant capital injections and negative margins for capturing market share have likely subsidized some of this. However, we doubt these levers explain all the improvement gains and price reductions. Even Gemini 1.5 Flash, released May 24, 2024, offers performance near GPT-4, costing about 85 times less for input data and 57 times less for output data than the original GPT-4. Although eliminating technology lock-in may not be possible, businesses can reduce their grip on technology adoption by using commercial models in the short run.
Avoiding lock-in risks
In some respects, the bitter lesson is part of this more considerable discussion about lock-in risks. We expect scaling to continue, at least for another couple of interactions. Unless you have a particular use case with obvious commercial potential, or operate within a high-risk and highly regulated industry, adopting the technology before the full scaling potential is determined and exhausted may be hasty.
Ultimately, training a language model or adopting an open-source model is like swapping a leash for a ball and chain. Either way, you’re not walking away without leaving some skin in the game. You may need to train or tune a model in a narrow domain with specialized language and tail knowledge. However, training language models involves substantial time, computational resources, and financial investment. This increases the risk for any strategy. Training a language model can cost hundreds of thousands to millions of dollars, depending on the model’s size and the amount of training data. The economic burden is exacerbated by the nonlinear scaling laws of model training, in which gains in performance may require exponentially greater compute resources—highlighting the uncertainty and risk involved in such endeavors. Bloomberg’s strategy of including a margin of error of 30 percent of their computing budget underscores the unpredictable nature of training.
Yet, even when successful, training may leave you stuck with your investment. Training may prevent you from using new models with better performance and novel features or even new scaling laws and strategies for training models. Don’t handcuff yourself to the wheel of your ship. While steering clear of proprietary pitfalls, you’re still shackled by the immense sunk costs of training, not to mention the ongoing obligations of maintenance and updates. Before training a model, you should ensure a clear and compelling need that cannot be met by existing pre-trained models or complex prompting strategies such as Everything of Thoughts (XoT) and Medprompt or more abstraction through less complicated modifications such as RAG.
The Anna Karenina principle
AI adoption can be likened to the famous quote by Russian author Leo Tolstoy in Anna Karenina: “All happy families are alike; each unhappy family is unhappy in its own way.” When applied to AI adoption, we might say: “All successful AI adoptions are alike; each failed adoption fails in its own way.” The “Anna Karenina principle” was popularized by Jared Diamond in his 1997 book Guns, Germs, and Steel. Diamond uses this principle to explain why so few wild animals have been successfully domesticated throughout history. Diamond argues that a deficiency in many factors can make a species undomestic. Thus, all successfully domesticated species are not due to possessing a particular positive trait, but because they lack any potential negative characteristics.
AI adoption is complex and requires more than downloading an open-source model from Hugging Face. Successful adoptions start with clear objectives and knowing precisely what the business needs to achieve. Don’t pursue AI because it’s trendy, but because you have specific goals. Successful adoption requires strong leaders who have a clear vision of how the technology will impact the business and who are committed to the strategy. They must manage risk and anticipate future needs with robust and scalable adoption strategies, allowing seamless integration and growth. They must also handle change management and ensure employees are onboard and understand the changes. Ethical considerations must also be addressed to ensure that AI is used responsibly. Everyone plays a vital role in adopting AI.
One guiding principle that may help leaders is Liebig’s Law, or the law of the minimum, a principle developed in agricultural science and later popularized by Justus von Liebig. It states that growth is dictated not by total resources available but by the scarcest resource or the limiting factor. You are already familiar with this law. It has been codified in clichés like “a chain is only as strong as its weakest link.” Liebig’s Law implies that the success of AI deployment is constrained by the most limiting factor in the adoption process. These factors include data, human capital, computational resources, governance, and compliance. Yet, even then, you may adopt the technology in a way that limits its potential or creates dependencies that are hard to escape. Businesses must balance innovation and practicality, avoiding vendor lock-in and focusing on modular, flexible technologies that allow them to remain agile and responsive to new developments. This approach ensures they can adapt quickly and cost-effectively to the ever-evolving AI landscape.
Rich Heimann is a leader in machine learning and AI whose former titles include Chief AI Officer, Chief Data Scientist and Technical Fellow, and adjunct professor. He is the author of Doing AI: A Business-Centric Examination of AI Culture, Goals, and Values and co-author of Social Media Mining using R.
Clayton Pummill is a licensed attorney specializing in complex machine learning, data privacy, and cybersecurity initiatives while building enterprise solutions and support practices for organizations facing machine learning regulations. Active in the technology startup space, he has developed patented technology, co-founded organizations, and brought them through to successful exits.
—
Generative AI Insights provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss the challenges and opportunities of generative artificial intelligence. The selection is wide-ranging, from technology deep dives to case studies to expert opinion, but also subjective, based on our judgment of which topics and treatments will best serve InfoWorld’s technically sophisticated audience. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Contact doug_dineley@foundryco.com.
{kind=link}
Are 10% of your software engineers lazy? 20 Jan 2025, 10:00 am
Nearly 10% of all software engineers are “ghosts” who “do virtually nothing” but collect $300K salaries. This, according to research from Stanford University. The paper takes particular aim at engineers who work remotely, declaring that 14% of them apparently spend more time gardening than tending to their Git repositories. Controversial? Yes. Accurate? Almost certainly not—at least, not based on this particular analysis of more than 50,000 engineers. The analysis makes for great sound bites but poor understanding of how software development works.
Do you believe in ghosts?
The point of the research is apparently to suggest that cutting these 9.5% “ghosts” would save $90 billion, as Stanford researcher Yegor Denisov-Blanch notes. It is, of course, very possible (even probable) that 10% of the developers within any company are low performers. Any job category will have a tier of relatively low-performing people. But it’s not at all reasonable to use code commits, as the researchers do, to paint performers as good or bad.
After all, writing code is not a software developer’s most important role—not for senior developers, anyway. Honeycomb CTO Charity Majors argues, “Being a senior engineer is not primarily a function of your ability to write code.” Instead, she continues, “It has far more to do with your ability to understand, maintain, explain, and manage a large body of software in production over time, as well as the ability to translate business needs into technical implementation.” As the Stack Overflow team puts it, the “hardest part of building software is not coding, [it’s figuring out] requirements.” The best engineers will figure out what to build and reduce that to as little code as possible.
In other words, Denisov-Blanch’s contention that less code is a strong indicator of poor performance might signal the opposite. At the least, it doesn’t confirm his and the other researchers’ finger-pointing at low levels of Git commits as dispositive proof of developers “ghosting” their employers. Nor does it confirm his “don’t-quote-me-on-this” argument that the research also shows that “the top 25% of engineers contributed about 50% to 60% of the output,” though that finding may be more intuitively correct, given the 80/20 rule.)
Less code may mean more productivity
Counting code commits, while an understandable approach, is flawed. Yes, the approach is a bit more sophisticated than that, but not as much as the researchers seem to think. For example, Nvidia Senior Engineering Manager Aaron Erickson points out that the researchers might find “another 10% of engineers who do add code, but it’s useless abstractions or vanity rework that adds negative value and confusion.” Stanford’s research would say that these are valuable engineers, but in reality, they might be doing more harm than good. Their employers would be better off if they decided to ghost instead of committing worse-than-useless code. The research doesn’t account for bad contributions, by Denisov-Blanch’s admission. They just expect bad commits are resolved during review.
All of this is a long way of saying the research may not say what the researchers believe. This wouldn’t be a big deal except that the headline is clearly meant to drive employers to revisit how they measure engineering productivity. (Denisov-Blanch says he did the research because he believes “software engineering could benefit from transparency, accountability, and meritocracy and [he] is trying to find a solution.”) That’s a great goal, but what about all the CEOs who may see the headline and demand that their ghost engineers be fired? Using code commits as the only metric could end up removing some of a company’s top engineers, not necessarily their worst ones.
{kind=link}
5 new features in EDB Postgres AI 20 Jan 2025, 10:00 am
More than half of enterprises (56%) run mission-critical workloads in hybrid environments, according to a 2024 EDB survey of enterprise executives. From data warehouses and data lakes to HTAP, OLTP, and AI development, hybrid models have become a strategic advantage, offering security and scalability while giving enterprises greater control over their most critical and differentiating asset—their data.
But hybrid success hinges on more than just the right strategy. It also requires tools that offer both agility and control. That’s exactly what EDB Postgres AI delivers with its Q4 release.
With features like the Hybrid Control Plane for single-pane-of-glass observability, 30x faster analytics, and generative AI functionality launched with just five lines of SQL, EDB Postgres AI gives developers fewer moving parts, faster time-to-insight, and greater control over where and how they work. Here’s a closer look at the five new features shaping EDB’s most powerful hybrid data platform yet.
Hybrid Control Plane: Observability, management, and automation across your Postgres data estate
Operating databases across hybrid, multi-cloud, and on-prem environments gives teams flexibility, but it also creates a sprawl of administrative tasks, dashboards, and alerting systems.
EDB’s Hybrid Control Plane solves this by enabling a hybrid database-as-a-service (DBaaS) in any environment–even on-prem. It introduces automated provisioning, backups, and point-in-time recovery (PITR), freeing teams from repetitive, costly admin tasks. By reducing the time spent on manual tasks, it boosts operational productivity by 30%.
The Hybrid Control Plane also provides a single pane of glass observability across all EDB Postgres AI deployments. Developers get a unified view of their environments, with more than 200 system metrics tracked in real time, along with health monitoring, alerting, and automated query diagnostics to boost application performance.
By consolidating daily maintenance, observability, and automation into one control plane, the Hybrid Control Plane enables DBAs and developers to operate with greater efficiency, faster troubleshooting, and tighter control over hybrid environments.
Key benefits:
- Single-pane-of-glass visibility for hybrid and multi-cloud EDB Postgres AI deployments.
- Automated backups, provisioning, and PITR to boost operational productivity by 30%.
- 5x faster problem identification and 8x faster performance with query diagnostics and alerting.
Analytics Accelerator: 30x faster queries compared to standard PostgreSQL
Traditional ETL pipelines slow down analytics. The process of copying, transforming, and syncing data to a separate warehouse delays insights, increases costs, and bloats infrastructure.
EDB’s Analytics Accelerator changes that. Instead of relying on ETL workflows or separate data warehouses, it enables teams to run analytical queries directly on core business data in EDB Postgres AI. By bringing analytical workloads closer to operational data, teams can query core business data at high speed without affecting production workloads.
With a vectorized query engine, it delivers queries that are 30x faster compared to standard PostgreSQL. The Analytics Accelerator also introduces tiered storage that offloads “cold” data to object storage, reducing reliance on high-cost SSDs. This approach lowers storage costs by 18x compared to solid-state drives while simplifying analytics across multiple data tiers.
Key benefits:
- 30x faster analytics compared to standard PostgreSQL — no ETL required.
- 18x more cost-effective storage by offloading cold data to object storage instead of SSDs.
- Real-time analytics on production data without sacrificing performance.
AI Accelerator: Build generative AI Functionality with five lines of SQL
The most advanced AI apps today rely on vector embeddings, but building and managing embedding pipelines is complex. It often requires developers to manage separate AI tools, multiple embeddings, and external AI services that put data sovereignty at risk.
EDB’s AI Accelerator provides the fastest way to test and launch multi-model GenAI applications — semantic search, chatbots, recommendation engines — directly within Postgres. No third-party pipelines. No third-party embeddings. Just five lines of SQL to launch generative AI apps that would normally require 130+ lines.
The AI Accelerator includes the EDB Pipelines extension, which is preloaded with pgvector, managed pipeline, and automated embeddings. These are integrated natively, allowing teams to store, query, and maintain embeddings within a single database. Embeddings update automatically when the source data changes, ensuring real-time freshness without manual intervention.
For enterprises prioritizing sovereignty, this means AI models can be deployed entirely within their control with no reliance on third-party AI services or cloud providers that expose data to outside vendors.
Key benefits:
- Build generative AI apps with just five lines of SQL instead of 130+.
- Automatic embedding updates avoids data staleness
- Sovereign AI deployment — embeddings stay within enterprise-controlled systems.
Secure Open Software Solution: Greater supply chain visibility and compliance
Security and open source supply chain visibility are fundamental needs for developers working in regulated environments. EDB Postgres AI delivers both to ensure that developers can build with secure open source software (OSS) confidently.
At the heart of this solution is the software bill of materials (SBOM), which provides a clear, verifiable view of every component used in EDB Postgres AI. Built on the Software Package Data Exchange (SPDX) open standard, the SBOM enables development teams to identify and mitigate potential security vulnerabilities with a detailed inventory of components and dependencies that make up the software package. This visibility gives developers and security teams greater confidence in their open source software supply chain.
Key benefits:
- Transparency with SBOM reports for open source supply chain visibility.
- Secure open source software with EDB’s Secure Open Software Solution, ensuring verified components and reduced vulnerabilities.
- Alignment with zero trust and FedRAMP standards, with work actively underway toward FedRAMP authorization.
Enhanced data migration tools: Streamlining legacy modernization
Modernization is a priority for many enterprises, but the path is rarely simple. Legacy databases like Oracle Database, Microsoft SQL Server, and IBM DB2 are often locked into proprietary features and rigid data models, making it hard to break free.
EDB’s enhanced Data Migration Service (DMS) and Data Sync tools provide a secure, low-downtime way to modernize legacy apps. These tools use change data capture (CDC) to sync data from Oracle and PostgreSQL databases, ensuring that data stays fresh during migration. Since Data Sync is embedded within the Hybrid Control Plane, teams can run live syncs of data as applications continue to run—reducing downtime and minimizing disruption.
Meanwhile, the Oracle Estate Migration Assessment helps teams identify “low-hanging fruit” for fast migrations. By targeting the least complex migrations first, enterprises can show early wins and build momentum toward larger transformations.
Key benefits:
- Up to 80% cost savings compared to Oracle Database licensing.
- Reduce downtime during migration with live, real-time syncs using CDC and Data Sync.
- Sovereign control, allowing enterprises to manage the entire migration without third-party reliance.
Five fab features
With this release, EDB Postgres AI elevates hybrid control to new heights. The Hybrid Control Plane enables teams to operate with cloud-like agility and unified control, bringing a cloud experience to any environment. Analytics Accelerator enables developers to extract real-time insights at 30x the speed. The AI Accelerator simplifies the complexity of generative AI development, enabling full-featured AI applications with just five lines of SQL. Together, these features deliver seamless orchestration across hybrid, multi-cloud, and on-prem environments—without ever relinquishing sovereignty.
And by integrating the latest features from PostgreSQL 17, EDB Postgres AI delivers core operational improvements that developers and DBAs will feel every day. Enhancements like the 100x faster sub-transaction cache, incremental backup support, and logical replication improvements to make it easier to run more complex queries, maintain high availability, and strengthen disaster recovery strategies.
This release redefines what hybrid control can achieve. With EDB Postgres AI, enterprises get the power of cloud agility, the certainty of control, and the freedom to innovate on their own terms.
Aislinn Shea Wright is VP of product management at EDB.
—
New Tech Forum provides a venue for technology leaders—including vendors and other outside contributors—to explore and discuss emerging enterprise technology in unprecedented depth and breadth. The selection is subjective, based on our pick of the technologies we believe to be important and of greatest interest to InfoWorld readers. InfoWorld does not accept marketing collateral for publication and reserves the right to edit all contributed content. Send all inquiries to doug_dineley@foundryco.com.
{kind=link}
From devops to CTO: 5 things to start doing now 20 Jan 2025, 10:00 am
I was promoted to CTO in my late twenties, and while it is common to see young CTOs leading startups these days, it was unusual in the ’90s. I was far less experienced back then, and still developing my business acumen. While I was a strong software developer, it wasn’t my architecture and coding skills that helped me transition to a C-level role.
Of all the technical skills I had back then, my devops skills were the most critical. Of course, we didn’t call it devops, as the term hadn’t been invented yet. We didn’t yet have CI/CD pipelines or infrastructure-as-code capabilities. Nonetheless, I automated our builds, scripted the deployments, standardized infrastructure configurations, and monitored systems performance.
Developing all that scaffolding enabled the development teams to focus on building and testing applications while operations managed infrastructure improvements. With automation in place and a team focused on the technology, I was able to focus on higher-level tasks such as understanding customer needs, partnering with product managers, learning marketing objectives, and learning about sales operations. When our CTO left for another opportunity, I was given the chance to step into the leadership role.
In my book, Digital Trailblazer, I elaborate on my journey from developer to CTO and CIO. Since the book came out, many readers have asked me for advice about how to accelerate their career trajectories. In this article, I focus on how high-potential employees in devops roles—including developers and engineers—can start making moves toward a CTO role.
Develop platforms teams want to use
If you want to be recognized for promotions and greater responsibilities, the first place to start is in your areas of expertise and with your team, peers, and technology leaders. However, shift your focus from getting something done to a practice leadership mindset. Develop a practice or platform your team and colleagues want to use and demonstrate its benefits to the organization.
Devops engineers can position themselves for a leadership role by focusing on initiatives that deliver business impacts and building systems that teams want to use. Look to deliver incremental small wins and guide solutions that help teams make continuous improvements in key areas.
Another important area of work is reviewing platform engineering approaches that improve developer experience and creating self-service solutions. Leaders seeking recognition can also help teams adopt shift-left security and improve continuous testing practices.
Recommendation: Don’t leave it to chance that leadership will recognize your accomplishments. Track your activities, adoption, and impacts in technology areas that deliver scalable and reusable patterns.
Shift your mindset to tech facilitator and planner
One of the bigger challenges for engineers when taking on larger technical responsibilities is shifting their mindset from getting work done today to deciding what work to prioritize and influencing longer-term implementation decisions. Instead of developing immediate solutions, the path to CTO requires planning architecture, establishing governance, and influencing teams to adopt self-organizing standards.
Martin Davis, managing partner at Dunelm Associates, says to become a CTO, engineers must shift from tactical problem-solving to big-picture, longer-term strategic planning. He suggests the following three questions to evaluate platforms and technologies and shift to a more strategic mindset:
- How will these technologies handle future expansion, both business and technology?
- How will they adapt to changing circumstances?
- How will they allow the addition and integration of other tools?
“There are rarely right and wrong answers, and technology changes fast, so be pragmatic and be prepared to abandon previous decisions as circumstances change,” recommends Davis.
Recommendation: One of the hardest mindset transitions for CTOs is shifting from being the technology expert and go-to problem-solver to becoming a leader facilitating the conversation around technology implementations. If you want to be a CTO, learn to take a step back to see the big picture and engage the team in recommending technology solutions.
Extend your technology expertise across disciplines
To ascend to a leadership role, gaining expertise in a handful of practices and technologies is insufficient. CTOs are expected to lead innovation, establish architecture patterns, oversee the full software development lifecycle, and collaborate and sometimes manage aspects of IT operations.
“If devops professionals want to be considered for the role of CTO, they need to take the time to master a wide range of skills,” says Alok Uniyal, SVP and head of IT process consulting practice at Infosys. “You cannot become a CTO without understanding areas such as enterprise architecture, core software engineering and operations, fostering tech innovation, the company’s business, and technology’s role in driving business value. Showing leadership that you understand all technology workstreams at a company as well as key tech trends and innovations in the industry is critical for CTO consideration.”
Devops professionals seeking to develop a deep and wide breadth of technology knowledge and expertise recognize it requires a commitment to lifelong learning. You can’t easily invest all the time required to dive into technology expertise, take classes in every technology, or wait for the right opportunities to join programs and teams where you can develop new skills. The most successful candidates find efficient ways to learn through reading, learning from peers, and finding mentors.
Recommendation: Add learning to your sprint commitments and chronicle your best practices in a journal or blog. Writing helps with retention and adds an important CTO skill of sharing and teaching.
Embrace experiences outside your comfort zone
In Digital Trailblazer, I recommend that leadership requires getting out of your comfort zone and seeking experiences beyond your expertise.
My devops career checklist includes several recommendations for embracing transformation experiences and seeking challenges that will train you to listen, question how things work today, and challenge people to think differently. For example, consider volunteering to manage an end-to-end major incident response to better understand being under pressure and finding problem root causes. That certainly will grow your appreciation of why observability is important and the value of monitoring systems.
However, to be a CTO, the more important challenge is to lead efforts that require participation from stakeholders, customers, and business teams. Seek out opportunities to experience change leadership:
- Lead a journey mapping exercise to document the end-user flows through a critical transaction and discover pain points.
- Participate in a change management program and learn the practices required to accelerate end-user adoption of a new technology.
- Go on a customer tour or spend time with operational teams to learn firsthand how well—and often not well—technology is working for them.
“One of the best ways I personally achieved an uplift in the value I brought to a business came from experiencing change, says Reggie Best, director of product management at IBM. “Within my current organization, that usually happened by changing projects or teams—gaining new experiences, developing an understanding of new technologies, and working with different people.”
John Pettit, CTO at Promevo, says to rise from devops professional to CTO, embrace leadership opportunities, manage teams, and align with your organization’s strategic goals. “Build business acumen by understanding how technology impacts company performance. Invest in soft skills like communication, negotiation, and strategic thinking.”
Petit recommends that aspiring CTOs build relationships across departments, read books on digital transformation, mentor junior engineers, develop a network by attending events, and find a mentor in a non-tech C-level leadership role.
Recommendation: The path to CTO requires spending more time with people and less time working with technology. Don’t wait for experience opportunities—seek them out and get used to being uncomfortable: it’s a key aspect of learning leadership.
Develop a vision and deliver results
CTOs see their roles beyond delivering technology, architecture, data, and AI capabilities. They learn the business, customers, and employees while developing executive relationships that inform their technology strategies and roadmaps.
Davis of Dunelm Associates recommends, “Think strategically, think holistically. Always look at the bigger picture and the longer term and how the decisions you make now play out as the organization builds, grows, and develops.”
My recent research of top leadership competencies of digital leaders includes strategic thinking, value creation, influencing, and passion for making a difference. These are all competencies that aspiring CTOs develop over time by taking on more challenging assignments and focusing on collaborating with people over technical problem-solving.
Beyond strategies and roadmaps, the best CTOs are vision painters who articulate a destiny and objectives that leaders and employees embrace. They then have the leadership chops to create competitive, differentiating technical, data, and AI capabilities while reducing risks and improving security.
You can’t control when a CTO opportunity will present itself, but if technology leadership is your goal, you can take steps to prepare. Start by changing your mindset from doing to leading, then look for opportunities to guide teams and increase collaboration with business stakeholders.
{kind=link}
Node.js set to stabilize type stripping 18 Jan 2025, 7:58 pm
Node.js, the popular JavaScript runtime, is moving to stabilize type stripping, a feature that allows developers to execute TypeScript files without source maps or additional configuration, speeding up the development process.
The Node.js runtime was fitted with type stripping as an experimental feature last August. Type stripping intentionally does not support syntaxes requiring JavaScript code generation. By replacing inline types with whitespace, Node.js can run TypeScript code without the need for source maps. The feature is “on its way” to being stable in Node.js, said Marco Ippolito of the Node.js steering committee in a January 13 blog post. TypeScript, Microsoft’s JavaScript variant with static typing and other enhancements, has become a cornerstone of modern development and has been the most-requested feature in the latest Node.js user surveys, Ippolito said.
Although TypeScript has been supported in Node.js for some time through loaders, these have relied heavily on configuration and user libraries. “This reliance led to inconsistencies between different loaders, making them difficult to use interchangeably,” Ippolito wrote in the blog post. “The developer experience suffered due to these inconsistencies and the extra setup required.”
Type stripping is intended to further improve the development experience by speeding up the cycle between writing code and executing it, with a goal of making development simpler and faster. Type stripping, Ippolito said, makes code clear and predictable, very close to how developers would write JavaScript.
TypeScript 5.7, the latest release, arrived in November.
{kind=link}
Secure AI? Dream on, says AI red team 18 Jan 2025, 4:21 am
The group responsible for red teaming of over 100 generative AI products at Microsoft has concluded that the work of building safe and secure AI systems will never be complete.
In a paper published this week, the authors, including Microsoft Azure CTO Mark Russinovich, described some of the team’s work and provided eight recommendations designed to “align red teaming efforts with real world risks.”
Lead author Blake Bullwinkel, a researcher on the AI Red Team at Microsoft, and his 25 co-authors wrote in the paper, “as generative AI (genAI) systems are adopted across an increasing number of domains, AI red teaming has emerged as a central practice for assessing the safety and security of these technologies.”
At its core, they said, “AI red teaming strives to push beyond model-level safety benchmarks by emulating real-world attacks against end-to-end systems. However, there are many open questions about how red teaming operations should be conducted and a healthy dose of skepticism about the efficacy of current AI red teaming efforts.”
The paper noted that, when it was formed in 2018, the Microsoft AI Red Team (AIRT) focused primarily on identifying traditional security vulnerabilities and evasion attacks against classical ML models. “Since then,” it said, “both the scope and scale of AI red teaming at Microsoft have expanded significantly in response to two major trends.”
The first, it said, is that AI has become more sophisticated, and the second is that Microsoft’s recent investments in AI have resulted in the development of many more products that require red teaming. “This increase in volume and the expanded scope of AI red teaming have rendered fully manual testing impractical, forcing us to scale up our operations with the help of automation,” the authors wrote.
“[To achieve] this goal, we developed PyRIT, an open-source Python framework that our operators utilize heavily in red teaming operations. By augmenting human judgement and creativity, PyRIT has enabled AIRT to identify impactful vulnerabilities more quickly and cover more of the risk landscape.”
Based on their experiences, Bullwinkel and the team of authors shared eight lessons they have learned, and elaborated on them in the paper through detailed explanations and case studies. They included:
Understand what the system can do and where it is applied: The first step in an AI red teaming operation is to determine which vulnerabilities to target, they said. They suggest: “starting from potential downstream impacts, rather than attack strategies, makes it more likely that an operation will produce useful findings tied to real world risks. After these impacts have been identified, red teams can work backwards and outline the various paths that an adversary could take to achieve them.”
You don’t have to compute gradients to break an AI system: To prove the point, the paper points to a study on the gap between adversarial ML research and practice. The study found “that although most adversarial ML research is focused on developing and defending against sophisticated attacks, real-world attackers tend to use much simpler techniques to achieve their objectives.” Gradient-based attacks are powerful, the authors said, “but they are often impractical or unnecessary. We recommend prioritizing simple techniques and orchestrating system-level attacks because these are more likely to be attempted by real adversaries.”
AI red teaming is not safety benchmarking: The two, authors said, are distinct yet “both useful and can even be complimentary. In particular, benchmarks make it easy to compare the performance of multiple models on a common dataset. AI red teaming requires much more human effort but can discover novel categories of harm and probe for contextualized risks.” Novel harms resulting from new capabilities in AI systems may not be fully understood, so the team must define them and build tools to measure them.
Automation can help cover more of the risk landscape: According to the authors, the “complexity of the AI risk landscape has led to the development of a variety of tools that can identify vulnerabilities more rapidly, run sophisticated attacks automatically, and perform testing on a much larger scale.” Automation in AI red teaming plays a critical role, which led to the development of an open source framework, PyRIT.
The human element of AI red teaming is crucial: Automation may be important, but the authors emphasized that, while “automation like PyRIT can support red teaming operations by generating prompts, orchestrating attacks, and scoring responses,” humans are needed for their cultural and subject matter knowledge, and for their emotional intelligence. They noted, “these tools are useful but should not be used with the intention of taking the human out of the loop.”
Responsible AI (RAI) harms are pervasive but difficult to measure: The bottom line here: RAI harms are more ambiguous than security vulnerabilities and it all has to do with “fundamental differences between AI systems and traditional software.” Most AI safety research, the authors noted, focus on adversarial users who deliberately break guardrails, when in truth, they maintained, benign users who accidentally generate harmful content are as or more important.
LLMs amplify existing security risks and introduce new ones: The advice here? The integration of generative AI models into a variety of applications has introduced novel attack vectors and shifted the security risk landscape. The authors wrote that “we therefore encourage AI red teams to consider both existing (typically system-level) and novel (typically model-level) risks.”
The work of securing AI systems will never be complete: The idea that it is possible to guarantee or ‘solve’ AI safety through technical advances alone is unrealistic and overlooks the roles that can be played by economics, break-fix cycles, and regulation, they stated. With that in mind, the paper pointed out that “in the absence of safety and security guarantees, we need methods to develop AI systems that are as difficult to break as possible. One way to do this is using break-fix cycles, which perform multiple rounds of red teaming and mitigation until the system is robust to a wide-range of attacks.”
Authors of the report concluded that AI red teaming is a nascent and rapidly evolving practice for identifying safety and security risks posed by AI systems. But they also raised a number of questions.
“How should we probe for dangerous capabilities in LLMs such as persuasion, deception, and replication?” they asked. “Further, what novel risks should we probe for in video generation models and what capabilities may emerge in models more advanced than the current state-of-the-art?”
Secondly, they asked how red teams can adjust their practices to accommodate different linguistic and cultural contexts. And thirdly, they wonder in what ways red teaming practices should be standardized to make it easier for teams to communicate their findings.
They also stated, “as companies, research institutions, and governments around the world grapple with the question of how to conduct AI risk assessments, we provide practical recommendations based on our experience red teaming over 100 genAI products at Microsoft. … We encourage others to build upon these lessons and to address the open questions we have highlighted.”
{kind=link}
JDK 24: The new features in Java 24 18 Jan 2025, 1:51 am
Java Development Kit (JDK) 24 is now in a second rampdown phase, with the feature set frozen at 24 features, ranging from a class-file API to a fourth preview of structured concurrency.
JDK 24 reached the second rampdown phase, targeting bugs with approval, this week, following an initial rampdown phase reached on December 5. Two release candidates are due in February. JDK 24 is due as a production release on March 18, 2025. With its two dozen features, JDK 24 far outdoes predecessor JDK 23, which arrived arrived September 17 with 12 official new features.
The five most recent additions include warnings upon the use of memory-access methods in sun.misc.unsafe, a fourth preview of structured concurrency, deprecating the 32-bit x86 port for removal, and improving Java’s resistance to quantum computing attacks by providing Java implementations of a quantum-resistant module-latticed-based digital signature algorithm and a quantum-resistant module-latticed-based key encapsulation mechanism.
Previously proposed features include flexible constructor bodies; ahead-of-time class loading and linking; removing the Windows 32-bit x86 port; synchronizing virtual threads without pinning; simple source files and instance main methods; permanently disabling the security manager; module import declarations; an experimental version of compact object headers; primitive types in patterns, instanceof, and switch; linking runtime images without JMODs; the generational Shenandoah garbage collector; scoped values; a key derivation function API; removal of the non-generational mode in the Z Garbage Collector; stream gatherers; a vector API; a class-file API; warnings to prepare developers for future restrictions on the use of JNI (Java Native Interface); and a late barrier expansion for the G1 garbage collector.
JDK 24 has been designated a non-long-term support (LTS) release. (The current LTS release is JDK 21, which shipped in September 2023.) Like JDK 23, JDK 24 will receive only six months of premier-level support from Oracle. Early access builds of JDK 24 can be found at jdk.java.net. JDK 24 is slated to be followed next September by the next LTS release, JDK 25.
With a warning upon use of memory-access methods in sun.misc.Unsafe, Java would issue a warning at runtime on the first occasion that any memory-access method in sun.misc.unsafe is invoked. All of these unsupported methods were terminally deprecated in JDK 23 and have been superseded by standard APIs. The sun.misc.Unsafe class was created to provide a mechanism for Java classes to perform low-level operations. Most of its methods are for accessing memory, either in the JVM’s garbage-collected heap or in off-heap memory, which is not controlled by the JVM. As the class name suggests, these memory-access methods are unsafe.
Structured concurrency, back for another preview, is intended to simplify concurrent programming by introducing an API for structured concurrency. With the structured concurrency concept, groups of related tasks running in different threads are treated as a single unit of work, thereby streamlining error handling and cancellation, improving reliability, and enhancing observability. The goal is to promote a style of concurrent programming that can eliminate common tasks arising from cancellation and shutdown, such as thread leaks and cancellation delays. Improving the observability of concurrent code also is a goal.
Deprecating the 32-bit x86 port for removal, which follows a proposal to deprecate the Windows 32-bit x86 port (see below), will deprecate the Linux 32-bit x86 port, which is the only 32-bit x86 port remaining in the JDK. It will also effectively deprecate any remaining downstream 32-bit x86 ports. After the 32-bit x86 port is removed, the architecture-agnostic Zero port will be the only way to run Java programs on 32-bit x86 processors. Deprecating the 32-bit x86 port in JDK 24 will allow for its removal in JDK 25.
The two features proposed for improving Java security through quantum-resistance include a quantum-resistant module-lattice-based key encapsulation mechanism (ML-KEM) and a quantum-resistant module-lattice-based digital signature algorithm (ML-DSA). ML-DSA would secure against future quantum computing attacks by using digital signatures to detect unauthorized modifications to data and to authenticate the identity of signatories. Key encapsulation mechanisms (KEMs) are used to secure symmetric keys over insecure communication channels using public key cryptography. Both features are designed to secure against future quantum computing attacks.
Flexible constructor bodies are in a third preview after being featured in JDK 22 and JDK 23, albeit with a different name in JDK 22, when the feature was called statements before super(...). The feature is intended to reimagine the role of constructors in the process of object initialization, letting developers more naturally place logic that they currently must factor into auxiliary static methods, auxiliary intermediate constructors, or constructor arguments. The proposal introduces two distinct phases in a constructor body: The prologue contains code that executes before the superclass constructor is invoked, and the epilogue executes after the superclass constructor has been invoked. The feature also would preserve the existing guarantee that code in a subclass constructor cannot interfere with superclass instantiation.
Ahead-of-time class loading and linking aims at improving startup times by making classes of an application instantly available in a loaded and linked state, when the HotSpot Java virtual machine starts. This would be achieved by monitoring the application during one run and storing the loaded and linked forms of all classes in a cache for use in subsequent runs.
The Windows 32-bit x86 port was deprecated for removal in JDK 21 with the intent to remove it in a future release. Plans call for removing the source code and build support for the Windows 32-bit x86 port. Goals include removing all code paths that apply only to Windows 32-bit x86, ceasing all testing and development efforts targeting the Windows 32-bit x86 platform, and simplifying the JDK’s build and test infrastructure. The proposal states that Windows 10, the last Windows operating system to support 32-bit operation, will reach its end of life in October 2025.
Synchronizing virtual threads without pinning involves improving the scalability of Java code that uses synchronized methods and statements by arranging for virtual threads that block in such constructs to release their underlying platform for use by other threads. This would eliminate almost all cases of virtual threads being pinned to platform threads, which severely restricts the number of virtual threads available to handle an application workload.
A fourth preview of simple source files and instance main methods would evolve the Java language so beginners can write their first programs without needing to understand language features designed for large programs. The feature was previously previewed in JDK 21, JDK 22, and JDK 23. The goal is to allow beginning Java programmers to write streamlined declarations for single-class programs and then seamlessly expand their programs to use more advanced features as their skills grow.
Permanently disabling the security manager involves revising the Java platform specification so developers cannot enable the security manager, while other platform classes do not refer to it. The security manager has not been the primary means of securing client-side Java code for many years, has rarely been used to secure server-side code, and has been costly to maintain, the proposal states. The security manager was deprecated for removal in Java 17.
Module import declarations, previously previewed in JDK 23, enhance the Java programming language with the ability to succinctly import all of the packages exported by a module. This simplifies the reuse of modular libraries but does not require the importing of code to be a module itself.
Compact object headers would reduce the size of object headers in the HotSpot VM from between 96 and 128 bits down to 64 bits on 64-bit architectures. The goal of the proposed feature is to reduce heap size, improve deployment density, and increase data locality.
A second preview of primitive types in patterns, instanceof, and switch in JDK 24 would enhance pattern matching by allowing primitive types in all patterns and contexts. The feature also would extend instanceof and switch to work with all primitive types. The goals of the feature include enabling uniform data exploration by allowing type patterns for all types, whether primitive or reference; aligning types with instanceof and aligning instanceof with safe casting; and allowing pattern matching to use primitive types in both nested and top-level pattern contexts. Other goals include providing easy-to-use constructs that eliminate the risk of losing information due to unsafe casts, following the enhancements to switch in Java 5 and Java 7, and allowing switch to process values of any primitive type. This feature was previously previewed in JDK 23.
With linking runtime images without JMODs, the plan is to reduce the size of the JDK by roughly 25% by enabling the jlink tool to create custom runtime images without JDK JMOD files. This feature must be enabled by default and some JDK vendors may choose not to enable it. Goals include allowing users to link a runtime image from modules regardless of whether those modules are standalone JMOD files, modular JAR files, or part of a runtime image linked previously. Motivating this proposal is the notion that the installed size of the JDK on the file system is important in cloud environments, where container images that include an installed JDK are automatically and frequently copied over the network from container registries. Reducing the size of the JDK would improve the efficiency of these operations.
Generational Shenandoah would enhance the garbage collector with experimental generational collection capabilities to improve sustainable throughput, load-spike resistance, and memory utilization. The main goal is to provide an experimental generational mode, without breaking non-generational Shenandoah. The generational mode is intended to become the default mode in a future release.
Scoped values enable a method to share immutable data both with its callees within a thread and with child threads. Scoped values are easier to reason about than local-thread variables. They also have lower space and time costs, particularly when used together with virtual threads and structured concurrency. The scoped values API was proposed for incubation in JDK 20, proposed for preview in JDK 21, and improved and refined for JDK 22 and JDK 23. Scoped values will be previewed in JDK 24.
With the key derivation function (KDF) API, an API would be introduced for key derivation functions, which are cryptographic algorithms for deriving additional keys from a secret key and other data. A goal of this proposal is allowing security providers to implement KDF algorithms in either Java code or native code. Another goal is enabling applications to use KDF algorithms such as the HMAC (hash message authentication code)-based extract-and-expand key derivation function (RFC 5869) and Argon2 (RFC 9106).
Removing the non-generational mode of the Z Garbage Collector (ZGC) is a proposal aimed at reducing the maintenance cost of supporting two different modes. Maintaining non-generational ZGC slows the development of new features, and generational ZGC should be a better solution for most use cases than non-generational ZGC, the proposal states. The latter eventually should be replaced with the former to reduce long-term maintenance costs. The plan calls for removing the non-generational mode by obsoleting the ZGenerational option and removing the non-generational ZGC code and its tests. The non-generational mode will expire in a future release, at which point it will not be recognized by the HotSpot JVM, which will refuse to start.
Stream gatherers would enhance the stream API to support custom intermediate operations. Stream gatherers allow stream pipelines to transform data in ways that are not easily achievable with the existing built-in intermediate operations. This feature was proposed as a preview in JDK 22 and JDK 23. The API would be finalized in JDK 24. Goals include making stream pipelines more flexible and expressive and allowing custom intermediate operations to manipulate streams of infinite size.
The vector API is designed to express vector communications that reliably compile at runtime to optimal vector instructions on supported CPU architectures, thus achieving performance superior to equivalent scalar computations. The vector API previously was incubated in JDK 16 through JDK 23. Goals of the proposal include clearly and concisely expressing a wide range of vector computations in an API that is platform-agnostic, that offers reliable runtime compilation and performance on x64 and AArch54 architectures, that degrades gracefully and still functions when a vector computation cannot be expressed at runtime, and that aligns with Project Valhalla, leveraging enhancements to the Java object model.
The class-file API, previously previewed in JDK 22 and JDK 23, would be finalized in JDK 24, with minor changes. This API provides a standard API for parsing, generating, and transforming Java class files. It aims to provide an API for processing class files that tracks the class file format defined by the Java Virtual Machine specification. A second goal is to enable JDK components to migrate to the standard API, and eventually remove the JDK’s internal copy of the third-party ASM library. Changes since the second preview include a renaming of enum values, removal of some fields, the addition of methods and method overloads, methods renamed, and removal of interfaces and methods deemed unnecessary.
Late barrier expansion for the G1 garbage collector is intended to simplify the implementation of G1’s barriers by shifting their expansion from early in the C2 compilation pipeline to later. The barriers record information about application memory accesses. Goals include reducing the execution time of C2 compilation when using the G1 collector, making G1 barriers comprehensible to HotSpot developers who lack a deep understanding of C2, and guaranteeing that C2 preserves invariants about the relative ordering of memory accesses, safepoints, and barriers. A fourth feature is preserving the quality of C2-generated JIT (just-in-time)-compiled code, in terms of speed and size.
The first JDK 24-targeted feature, officially called “Prepare to Restrict the Use of JNI,” calls for issuing warnings about uses of JNI and adjusting the foreign function and memory (FFM) API, featured in JDK 22, to issue warnings in a consistent manner. These warnings are intended to prepare for a future release that ensures integrity by default by uniformly restricting JNI and the FFM API. Goals of the plan include preserving JNI as a standard way to interoperate with native code, preparing the Java ecosystem for a future release that disallows interoperation with native code by default, and aligning the use of JNI and the FFM API so library maintainers can migrate from one to the other without requiring developers to change command-line options.
The most recent LTS release, JDK 21, arrived in September 2023 and is due to get at least five years of Premier support from Oracle. The next LTS version, JDK 25, is due in September 2025. LTS releases have dominated Java adoption, which means adoption of JDK 23 and JDK 24 could be on the low end as users await JDK 25.
{kind=link}
Federated learning: The killer use case for generative AI 17 Jan 2025, 10:00 am
Let’s imagine a fictional company, Global Retail Corporation, a multinational retail chain struggling with its initial approach to AI integration. They built custom generative AI applications on their cloud provider using OpenAI’s APIs for broader analysis, providing access to their LLMs (large language models) and ChatGPT to get more strategic and valuable answers to their business questions. The process was costly and complex, and it delivered suboptimal results. That all changed when they adopted federated learning.
The strategy of federation in AI deployments
Federated learning is emerging as a game-changing approach for enterprises looking to leverage the power of LLMs while maintaining data privacy and security. Rather than moving sensitive data to LLM providers or building isolated small language models (SLMs), federated learning enables organizations to train LLMs using their private data where it resides. Everyone who worries about moving private enterprise data to a public space, such as uploading it to an LLM, can continue to have “private data.” Private data may exist on a public cloud provider or in your data center.
The real power of federation comes from the tight integration between private enterprise data and sophisticated LLM capabilities. This integration allows companies to leverage their proprietary information and broader knowledge in models like GPT-4 or Google Gemini without compromising security. More importantly, it means not having to deal with moving petabytes of data to a public cloud that’s also hosting an LLM.
For our fictional company, their customer transaction data, inventory systems, and supply chain information could contribute to training advanced language models while remaining within their secure cloud environment. They leverage the data where it exists, cloud or no cloud, and thus, there is no need to move the data to another cloud provider or even to another space within their public cloud provider. The resulting system provides more profound insights and accurate predictions than building standalone AI applications.
Financial and operational advantages
The federated approach offers significant cost advantages. Organizations can leverage existing cloud resources where their data already resides rather than maintaining separate AI infrastructure and paying for extensive data transfers.
Recent developments have made federated learning more accessible. New frameworks enable seamless integration between edge-based SLMs and cloud-based LLMs, creating a hybrid architecture that maximizes benefits while minimizing risks. This approach is particularly valuable for organizations dealing with sensitive data or needing to comply with regulations, but mainly, it’s just architecturally simpler and thus easier and faster to build and deploy.
As a generative AI/cloud architect, I’ve found that the core issue in designing and deploying these beasts is their innate complexity, which is unavoidable as you add many moving parts, such as replicating your business data for training data for an LLM. More complexity means more cost, worse security, and enterprises being architecturally lazy overall.
The next generation of enterprise AI architecture
As enterprises struggle to balance AI capabilities against data privacy concerns, federated learning provides the best of both worlds. Also, it allows for a choice of LLMs. You can leverage LLMs that are not a current part of your ecosystem but may be a better fit for your specific application. For instance, LLMs that focus on specific verticals are becoming more popular. However, they are typically hosted by another provider.
The future of enterprise AI lies not in isolated solutions or purely cloud-based approaches but in federated systems that combine both strengths. Organizations that embrace a federated approach will find themselves better positioned to extract value from their data while maintaining required levels of security and compliance.
For companies like Global Retail Corp., the switch to federated learning isn’t just about technology, it’s about finding a more efficient, secure, and effective way to harness the power of AI. As more enterprises face similar challenges, federated learning is poised to become the standard approach for implementing generative AI in the enterprise (according to me). Given the architectural and cost advantages of using these mechanisms to couple your enterprise’s data with a public LLM’s vast knowledge, I’m not sure why it’s not a bigger deal. It’s the easiest way.
A practical road map for federated learning
The path to federated learning begins with thoroughly understanding your current data landscape. Start by conducting a comprehensive assessment of where your data lives, how it’s governed, and how it flows through your organization. This foundation will reveal the potential integration points for federated learning systems and highlight gaps in your infrastructure.
The technical groundwork requires careful attention to detail. Your organization needs standardized data labeling practices, robust edge computing capabilities where necessary, and reliable network connectivity between data sources. Create testing environments that accurately reflect your production data distribution.
Organizational readiness is equally important. Create teams that bring together data scientists, security experts, and domain specialists. These cross-functional groups should work together to establish governance frameworks and metrics for success. Don’t forget to create clear data-sharing agreements between departments. These will be essential for federated learning to work effectively.
When you’re ready to begin implementation, start small. Identify contained use cases that can serve as pilots and carefully select technology partners that understand your specific needs. Define clear success criteria for these initial projects and establish robust monitoring frameworks to track progress.
Remember, the goal isn’t to rush into complex federated learning systems but to build a solid foundation to support your enterprise’s future AI. A measured approach focusing on infrastructure, skills, and organization will position you for success as federated learning technology evolves and matures.
Federated learning represents a strategic evolution for enterprises looking to harness the full power of their data and use it where it exists. As federated learning continues to gain traction, companies that adopt a thoughtful strategy will be better equipped to unlock deeper insights and drive meaningful business outcomes.
The future belongs to those willing to embrace this paradigm shift and leverage emerging technologies to their full potential. Will you be a part of it?
{kind=link}
Python eats the world 17 Jan 2025, 10:00 am
In this week’s Python Report: Everyone’s favorite snake-named language is getting closer to being everyone’s favorite language, period. We also have a guide to unpacking the power of Python’s abstract base classes, and a tutorial for developers who want to use Cython to speed up their Python code. Or how about a deep dive into the whole extended family of Python distributions? Who knows, you might find the Python re-packaging that solves your trickiest problem yet.
Top picks for Python readers on InfoWorld
Python: Language of the year, 2024
Who’s surprised? Not us! What’s more surprising is the mega-star languages Python is pushing out of the spotlight.
The power of Python’s abstract base classes
Learn the ABCs of Python’s abstract base class system, which (among other things) makes it easier to create types that mimic the behaviors of built-in types.
How to speed up Python with Cython
Never settle for slow! Learn how compiling Python to C gives all kinds of programs a major boost, but especially the ones that crunch numbers.
10 Pythons for every programming need
Want a Python you can take with you? A Python specifically for Microsoft Windows, with all its quirks? A Python for data scientists? There really is a Python for every occasion.
More good reads and Python updates elsewhere
uv-migrator: Automatically migrate to the UV package manager
This handy utility automatically migrates Python projects that use Poetry, pipenv, or plain old requirements.txt to the new uv package manager.
Run Python programs easily in the browser
A simple recipe for running Python in-browser with Pyodide.js, including handling pip-installed packages and file access.
Zython: WebAssembly-powered Python
Built with Zig, this experimental Python interpreter runs in WebAssembly environments. Much is still missing, but if you’re curious about Python in Wasm, now’s your chance to give it a whirl.
Offtopic flashback: How multi-user dungeons taught me to code
Wherein our hero takes a crash course in C via the source code of CircleMUD.
{kind=link}
Here’s how Google is using LLMs for complex internal code migrations 17 Jan 2025, 6:00 am
Code migration is a critical process in maintaining software applications. It helps improve performance and resilience, keeps systems up to date, and removes stale or irrelevant code.
But it can be complex and time-consuming on a number of levels, not the least of which is the fact that the code is very often sprawled across a variety of environments. And, while AI has emerged to support a number of lower-level programming tasks, the technology has yet to be able to handle the convoluted, confusing job of code migration.
But now Google says it may have overcome that challenge, offering up a new step-by-step process and common toolkit in which large language models (LLMs) find files that need to be changed. Already, the tech giant says its process has accelerated migrations by 50%.
“This approach has the potential to radically change the way code is maintained in large enterprises,” a group of authors from Google Core and Google Ads wrote in a new “experience report” describing their approach. “Not only can it accelerate the work of engineers, but make possible efforts that were previously infeasible due to the huge investment needed.”
Ultimately, Google’s goal was to identify opportunities for LLMs to provide additional value and support scale without requiring difficult-to-maintain abstract syntax trees (AST). These are widely used to represent the structure of a program or snippet of code, but they are deterministic — that is, outcomes are already identified — and code migration use cases span much more complex constructs that are difficult to represent with ASTs, the authors explained.
“Achieving success in LLM-based code migration is not straightforward,” the authors noted. “The use of LLMs alone through simple prompting is not sufficient for anything but the simplest of migrations. Instead, as we found through our journeys, and as described in the case studies in this paper, a combination of AST-based techniques, heuristics, and LLMs are needed to achieve success. Moreover, rolling out the changes in a safe way to avoid costly regressions is also important.”
Google defined success as AI saving at least 50% of the time for the end-to-end work. This comprised the code rewrite, the identification of migration locations, reviews, and final rollout. That milestone was ultimately achieved, as reported by engineers. In the end, 80% of code modifications were fully AI-authored.
“Anecdotal remarks from developers suggest that even if the changes are not perfect, there is a lot of value in having an initial version of the changelist already created,” the report said.
Use case: Google Ads IDs
One of Google’s largest business units, Google Ads, is built on a code base of more than 500 million lines of code. It has dozens of numerical unique ID types that reference different resources (known as “handles”) such as users, merchants, and campaigns. These typically are defined as 32-bit integers in C++ and Java; however, they needed to be converted to 64-bit IDs to avoid scenarios where the value of the ID was too large to be accommodated using 32-bits, the report authors explained.
But there are numerous challenges to moving from 32-bit to 64-bit. Within Google, IDs are very generally defined and not easily searchable. This makes the process of finding them through static tooling “non-trivial.” Compounding this is the fact that Google Ads has tens of thousands of code locations, making tracking of changes extremely difficult.
This is one of the areas where Google applied its LLM-powered code migration process. In the first step, an engineer finds the IDs, file supersets, and locations they want to migrate. The changes are then generated in the LLM, creating a feedback loop of testing and iteration. The engineer finally reviews the LLM-generated code (as they would any other code), changing and correcting as needed. Then, the changes are then split (sharded) and sent off for final review by the owners of each part of the codebase.
Updating to JUnit4
In another example, a group of teams at Google had a “substantial” set of test files that still used the now outdated JUnit3 library, a unit testing open-source framework for Java. Updating them manually would be a big investment, and old tests can negatively impact the codebase, the Google authors explained.
“They are technical debt and tend to replicate themselves, as developers might inadvertently copy old code to produce new code,” they wrote.
Google developers used the LLM to update what they called a “critical mass” of JUnit3 tests to the new JUnit4 library. With this technique, they were able to migrate 5,359 files, modifying more than 149,000 lines of code in 3 months.
Cleaning up stale code
A further use case involved cleanup of experimental code that had gone stale. Again, this process is time-consuming, so AI was asked to perform the following steps:
- Find code locations where flags (experiments) are referenced
- Delete code references to the flag
- Simplify any conditional expressions that depend on the flag
- Clean any dead code
- Update tests and delete useless tests
Techniques can be applied anywhere
The framework is not restricted to Google’s software. As the report authors note: “We believe the techniques described are not Google-specific, and we expect that they can be applied to any LLM-powered code migration at large enterprises. The toolkit is versatile and can be used for code migrations with varying requirements and outputs.”
{kind=link}
Google rolls out Vertex AI RAG Engine 17 Jan 2025, 1:55 am
Google has formally introduced Vertex AI RAG Engine, a developer tool aimed at streamlining the complex process of retrieving relevant information from a knowledge base and feeding it to an LLM (large language model).
Introduced in a January 15 blog post as a component of the Vertex AI platform, Vertex AI RAG Engine is a managed orchestration service and data framework for developing context-augmented LLM applications. In elaborating on the Vertex AI RAG Engine, Google said generative AI and LLMs are transforming industries, but that challenges such as hallucinations (generating incorrect or nonsensical information) and limited knowledge beyond training data can hinder enterprise adoption. Vertex AI RAG Engine implements retrieval-augmented generation to empower software and AI developers to build grounded, generative AI solutions.
Google noted the following key advantages of Vertex AI RAG Engine:
- Ease of use, with developers able to get started via an API enabling rapid prototyping and experimentation.
- Managed orchestration, to handle data retrieval and LLM integration.
- Customization and open source support, with developers able to choose from parsing, chunking, annotation, embedding, vector storage, and open source models. Developers also can customize their own components.
- Integration flexibility, to connect to various vector databases such as Pinecone and Weaviate, or use Vertex AI Search.
In the introductory blog post, Google cited industry use cases for Vertex AI RAG Engine in financial services, health care, and legal. The post also provided links to resources including a getting started notebook, example integrations with Vertex AI Vector Search, Vertex AI Feature Store, Pinecone, and Weaviate, and a guide to hyperparameter tuning for retrieval with RAG Engine.
{kind=link}
Snowflake open sources SwiftKV to reduce inference workload costs 16 Jan 2025, 5:00 pm
Cloud-based data warehouse company Snowflake has open-sourced a new proprietary approach — SwiftKV — designed to reduce the cost of inference workloads for enterprises running generative AI-based applications. SwiftKV was launched in December.
The development of SwiftKV assumes significance as inferencing costs for generative AI applications are still high and work as a deterrent for enterprises either looking to scale these applications or infuse generative AI into newer use cases, the company explained.
SwiftKV goes beyond KV cache compression
SwiftKV, according to Snowflake’s AI research team, tries to go beyond key-value (KV) cache compression — an approach used in large language models (LLMs) to reduce the memory required for storing key-value (KV) pairs generated during inference.
The reduction in memory is made possible by storing earlier computed data via methods such as pruning, quantization, and adaptive compression. What this essentially does is it makes optimized LLMs handle longer contexts and generate output faster while using a lesser memory footprint.
However, Snowflake claims that a simple KV cache compression might not be enough to “meaningfully” curtail the cost of inferencing workloads as most workloads end up using more input tokens than output tokens. And processing costs of input tokens remain unaffected by KV cache compression.
In contrast, SwiftKV reduces inference computation during prompt processing (input tokens) by combining techniques such as model rewiring and knowledge-preserving self-distillation.
As part of these techniques, SwiftKV reuses the hidden states of earlier transformer layers to generate KV cache for later layers, the company’s AI research team explained, adding that this eliminates redundant computations in the pre-fill stage, which in turn reduces the computational overhead by at least 50%.
In order to maintain the accuracy of the LLMs, SwiftKV ensures that the rewired or optimized model replicates the behavior of the original LLM by using self-distillation, the research team further explained.
SwiftKV concept is not new
Analysts view SwiftKV as yet another clever means of optimizing model inferencing costs in line with many similar efforts, such as prompt caching, flash attention, model pruning, and quantization. The concept itself is not new.
“This idea is not new and Snowflake is certainly not the first to illustrate its value, of course. SAP, for example, introduced this idea with its model plug-in, Finch, earlier in 2024,” said Bradley Shimmin, chief analyst at Omdia.
However, despite Snowflake’s claims of minimal accuracy loss of SwiftKV-optimized LLMs, Shimmin warned that there could be tradeoffs in terms of how complex they are to implement, how much they degrade capability, and how compatible they are with the underlying inferencing architecture.
“Methods like quantization are super-popular because they do not impose that many tradeoffs. So, if customers find this technique from Snowflake to be of similar value, I imagine they will use it perhaps even alongside other techniques as required by whatever project they have at hand,” Shimmin explained.
How can enterprises use SwiftKV?
Enterprises do have the choice of accessing SwiftKV either through Snowflake or they can deploy it on their model checkpoints on Hugging Face or their optimized inference on vLLM.
While model checkpoints on Hugging Face refer to a saved set of weights of a model during its training, vLLM is a library meant for LLM inferencing and serving.
Snowflake customer enterprises particularly can take advantage of SwiftKV by accessing the new SwiftKV-optimized models, currently Llama 3.3 70B and Llama 3.1 405B, from inside Cortex.
Snowflake, earlier in December, had open-sourced the model weights and vLLM code.
However, it was not ready, until now, to release the SwiftKV-optimized models in Cortex AI or release the training code used to develop SwiftKV.
Presently, the company is also open-sourcing the training library called ArcticTraining, which allows engineers to build their own SwiftKV models.
{kind=link}
Build API clients with Microsoft Kiota 16 Jan 2025, 10:00 am
Service-oriented architectures are at the heart of modern application development. By building applications out of a mix of services, we can take advantage of the current generation of platforms to build serverless, scalable, distributed applications. Microsoft has long been at the forefront of API-first design and development, with low-level tools to build and deliver APIs.
A key part of Microsoft’s API strategy is the OpenAPI description language. Based on Swagger, OpenAPI makes it easy to build applications that have self-describing APIs, delivering descriptions as a standard build artifact, alongside binaries. Having that API description is useful, as tools like Visual Studio can consume the description and build a scaffolding for clients to use with HTTP APIs. But what if you’re building code with a tool or a language that’s not supported?
I was looking at the documentation for the latest release of the Teams SDK and saw a reference to an open source tool called Project Kiota to add HTTP API support. The GitHub repository for Kiota shows that it’s a standalone CLI-based tool for working with OpenAPI descriptions. It supports many popular languages, including Dart, Go, and Ruby. The status page shows work underway for Swift and TypeScript, as the underlying framework is designed to quickly add new language support.
Understanding Project Kiota
Microsoft says the aim of the project is “to eliminate the need to take a dependency on a different API client library for every API that you need to call.” The underlying intent is that you don’t need to learn a new REST library for each language you use; you can instead rely on generated methods and objects. Kiota provides a basic set of tools for serializing and deserializing JSON payloads.
Usefully, you can specify which elements of an OpenAPI description you’re implementing, simplifying the generated code and avoiding over-complicating your application. Like .NET’s minimal APIs, Kiota is a tool for simplifying your development workflow, not adding more complications.
Microsoft makes it easy to get started with Kiota. As it’s designed to work with many different languages and toolchains, there is a mix of official and unofficial ways to install and use it. If the methods listed don’t work for you, it’s a .NET application and the source code is on GitHub, so you can compile it yourself.
Using Kiota in your development toolchain
The first (and probably most likely) option is to simply download the binaries. Versions are available for Linux, macOS, and Windows. The documentation doesn’t mention Arm builds for Linux or Windows, but you can download a Linux Arm build from GitHub. Windows Arm users will need to download an x64 build and use Windows’ Prism emulator.
An alternative is to use a prebuilt Docker image. Microsoft provides some sample command line calls to build client libraries from local OpenAPI files and from online-hosted descriptions. If you’re using them from Windows, it’s a good idea to have Docker in WSL2 already installed and run the container inside your Linux environment, exporting the output to your choice of development environments.
If you are using a recent build of the .NET SDK, you can add Kiota to your toolchain from the .NET CLI. Again, there are versions for most common .NET development platforms, and you need the right runtime identifier to download the right version. For example, if you’re using a modern Apple Silicon Mac as a .NET development platform, use the osx-arm64 identifier to install the correct version.
You can automate the process of building client code by using Kiota from a GitHub Action. Start by defining the steps associated with checking out code, using a Microsoft-provided Kiota build to update clients when you check out code and working with a local branch. This ensures you’re always working against the most up-to-date version of the APIs your code is consuming.
There are community-built alternatives, using services like the asdf tool-version manager or the Homebrew macOS package manager. These tools use their own repositories, but if they’re your choice of toolchain package management, you can quickly add Kiota to an install script so you or your team can quickly refresh and update development devices.
Users of Visual Studio Code can take advantage of a preview extension that plugs Kiota directly into your editor. It’s not the same tool used by Visual Studio’s REST API Client Code Generator, which will install Kiota when needed, but it means that both of Microsoft’s main development tools can take advantage of its capabilities.
Working with Kiota-managed APIs
Using Kiota is relatively straightforward. If you’re using .NET, start by installing the Kiota command-line tool and ensure your project has the right settings for both the target framework and the language version. Modern .NET applications need to be .NET 6 or later (though you can use older versions with the right versions of .NET Standard). Languages have a similar requirement, with C# needing to be Version 7.3 or later.
Your code will need to include Kiota’s dependencies, which can be installed using its bundle. Microsoft details the required abstractions and packages for the supported languages, serialization options, and HTTP implementations. If you are using an authenticated API, you need to include support for various identity management tools. Using the bundles simplifies things considerably, though there are languages where you need to add dependency support as needed, such as Python and PHP.
You can now generate an API client from OpenAPI YAML. This can be a local file (most likely if you’re authoring your own OpenAPI descriptions) or a URL for public APIs. Client classes are generated using the command-line tool, defining the target language, the name of the client class, its namespace, the location of the OpenAPI YAML, and, finally, the output directory. You can use other options to tune the output, for example, reducing size by only building to the latest version of Kiota or reducing backwards compatibility.
Kiota builds the code needed to work with your API, and you can start to include it in your application. You will need to import the generated namespace, authorize the connection, and create a client object based on the class generated by Kiota. It’s all quite simple really, with calls to the API encapsulated in methods in the Kiota-generated class, with support for standard HTTP actions so you can get and post data from the API.
Choose your language
If you’re using another language, such as Python, the process is similar. With Python, however, there is no bundle of prerequisites and dependencies, so you need to use pip to install the appropriate Kiota libraries. The process of building and using a Kiota client is much the same as for .NET, importing classes as necessary and using them asynchronously.
The Kiota experience stays the same for each supported language: First, load dependencies into your project, build the client from an OpenAPI definition, and then import and use the generated client classes. Once you’ve defined the imports you’re using, you can refresh the client without affecting your application code—unless there’s an updated version of the API you’re calling.
So why use Kiota? The promise of OpenAPI was always that a common API description language would allow developers to automate the process of building clients. Kiota certainly delivers here, with a language-agnostic architecture that works with most common development toolchains. By delivering a standard set of classes, it keeps the learning curve to a minimum: You know what the output will be and how to use it in your code.
There are uses beyond the coding workflow. Kiota can quickly build tests for service-oriented architectures, dropping into a CI/CD pipeline to ensure services build correctly and are fit for use. Similarly, it can be used as part of a low-code environment, building and validating connectors ready for use in workflows.
That last option fits in well with agentic AI. Instead of generating new API calls every time a service runs in an AI query, Kiota clients could serve as the API equivalent of a semantic memory, capturing the API structure and leaving a client library ready for use by the AI in future operations. Giving agents an API memory should reduce risk and help manage and secure calls to services, keeping results consistent.
{kind=link}
Digital Transformation in Prisons: How Kazakhstan is Leading the Way 16 Jan 2025, 5:42 am
Technology innovations have made the digital transformation of public services essential to enhancing safety, efficiency, and accountability. Kazakhstan has taken a monumental step forward in this regard by implementing a continuous video surveillance system across 78 correctional facilities nationwide. This groundbreaking initiative has set a new benchmark for prison management, significantly improving safety conditions and operational transparency.
A digital leap for safer prisons
In response to a national mandate from the President in 2020, the Ministry of Internal Affairs launched a comprehensive video surveillance project. The system includes over 39,500 high-definition cameras strategically installed across correctional institutions and their perimeters. These cameras are connected to advanced AI-driven analytics, providing real-time facial recognition, event detection, and license plate identification capabilities.
The results are nothing short of remarkable: since its implementation, the system has identified over 32,000 violations of detention protocols, prevented 62 suicides and six escape attempts, and de-escalated 27 potentially violent conflicts. It has also reduced corruption and abuse, fostering humane treatment of inmates and improving the behavior of staff. For the first half of 2024, no cases of torture by staff were reported, a testament to the system’s effectiveness.
Innovation meets human-centered design
Kazakhstan’s video surveillance initiative goes beyond mere technological deployment. It represents a harmonious blend of innovation, process improvement, and personnel training. Prison staff have been equipped with the tools and knowledge to harness the system’s full potential, enabling proactive incident management and fostering a culture of accountability.
The initiative also supports the broader goal of rehabilitation. By improving the physical, psychological, and social conditions within prisons, the system aligns with global trends emphasizing inmate welfare and reintegration into society.
Overcoming challenges with strategic vision
Before the project, sporadic and poorly maintained surveillance systems plagued correctional facilities, resulting in inconsistent monitoring and inadequate evidence for investigations. Kazakhstan addressed these challenges by deploying a centralized, secure infrastructure that ensures uninterrupted video transmission to a Situation Center under the Ministry of Internal Affairs.
This hub manages real-time monitoring and analytics while safeguarding data integrity and privacy. The adoption of a fiber-optic private network further enhances reliability and security, creating a scalable framework for future innovations.
Charting the road ahead
Kazakhstan’s video surveillance initiative is just the beginning. Plans are underway to integrate more advanced algorithms for object and event recognition and to connect the system with other IT infrastructures, such as access control solutions. These advancements will further strengthen the nation’s ability to maintain order, prevent misconduct, and foster trust in correctional institutions.
The nation’s achievement offers valuable lessons for countries aiming to modernize their correctional facilities. By leveraging cutting-edge technology, combining it with strategic governance, and emphasizing human-centered implementation, Kazakhstan has set a precedent for others to follow.
For a deeper dive into the strategies, implementation, and impact of this project, download the full report. Explore how Kazakhstan is redefining correctional facility management through innovation and strategic foresight.
For a deeper dive into the strategies, implementation, and impact of this project, download the full report: Global Trends in the Digital Transformation of Correctional Facilities: The Value of Video Surveillance.
{kind=link}
Page processed in 0.028 seconds.
Powered by SimplePie 1.3.1, Build 20130517180413. Run the SimplePie Compatibility Test. SimplePie is © 2004–2025, Ryan Parman and Geoffrey Sneddon, and licensed under the BSD License.